MICRO • 07/24/2023
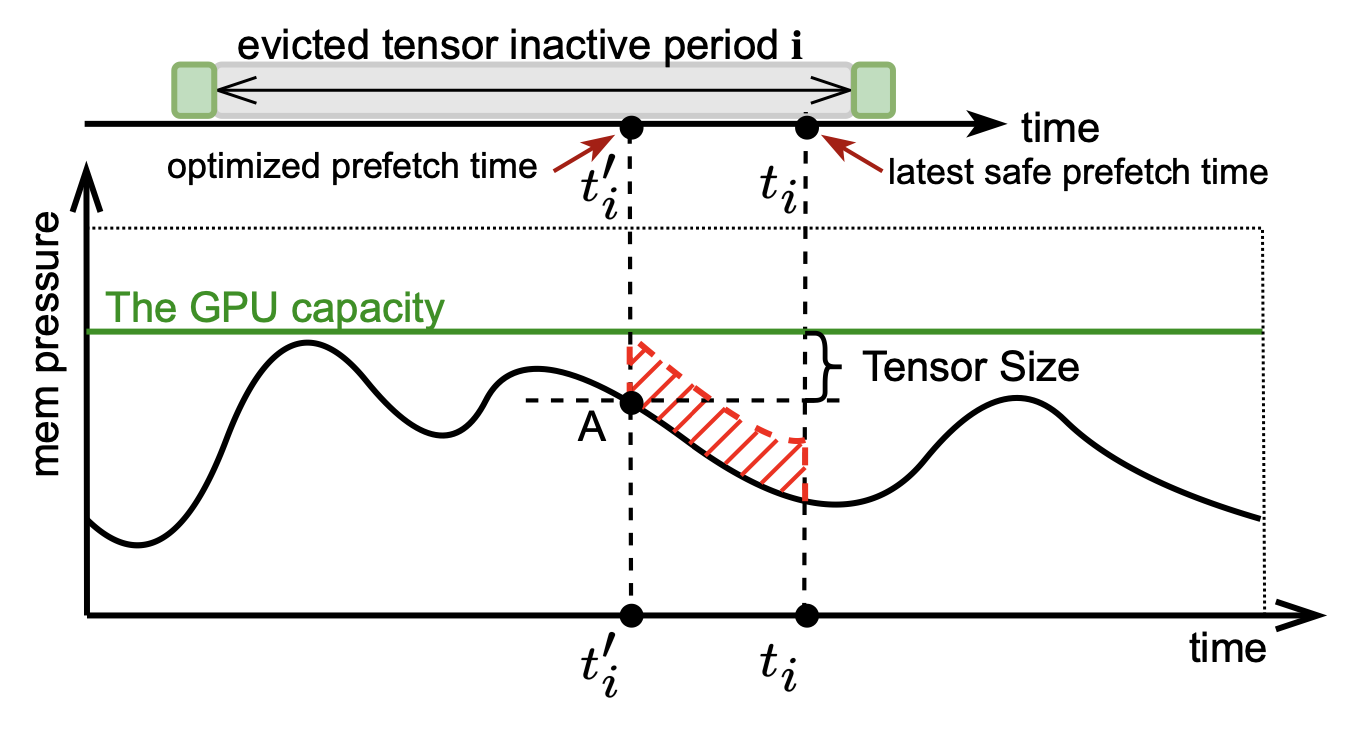
G10 integrates the host memory, GPU memory, and flash memory into a unified memory space, to scale the GPU memory capacity while enabling
transparent data migrations. Based on this unified GPU memory and storage architecture, G10 utilizes compiler techniques to characterize the tensor behaviors
in deep learning workloads and schedule data migrations in advance.
MICRO • 07/24/2023
We present an automated learning-based SSD
hardware configuration framework, named AutoBlox, that
utilizes both supervised and unsupervised machine learning
(ML) techniques to drive the tuning of hardware configurations for SSDs.
AutoBlox automatically extracts the unique
access patterns of a new workload using its block I/O traces,
maps the workload to previous workloads for utilizing the
learned experiences, and recommends an optimized SSD
configuration based on the validated storage performance.
SOSP • 07/16/2023
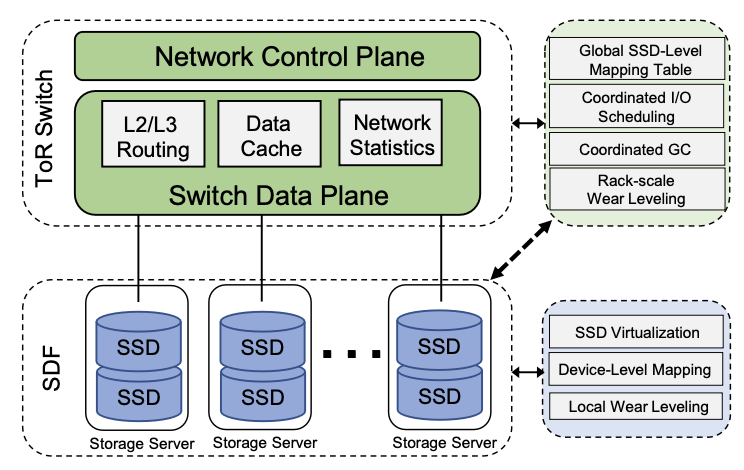
We co-design the SDN and SDF stack by re-defining the functions of their control plane and data plane,
and splitting up them within a new architecture named RackBlox. RackBlox decouples the storage management functions of flash-based solid-state drives (SSDs), and allow the SDN
to track and manage the states of SSDs in a rack. Therefore, we can enable the state sharing between SDN and SDF, and
facilitate global storage resource management.

Research • 06/18/2023
The Workshop on Hot Topics in System Infrastructure (HotInfra'23) provides a unique forum for cutting-edge
research on system infrastructure and platforms. Researchers and engineers can share their recent research
results and experiences and discuss new challenges and opportunities in building next-generation system
infrastructures, such as AI infrastructure, software-defined data centers, and edge/cloud computing
infrastructure. The topics span across the full system stack with a focus on the design and implementation of
system infrastructures. Relevant topics include hardware architecture, operating systems, runtime systems,
and emerging applications.
HotOS • 04/21/2023
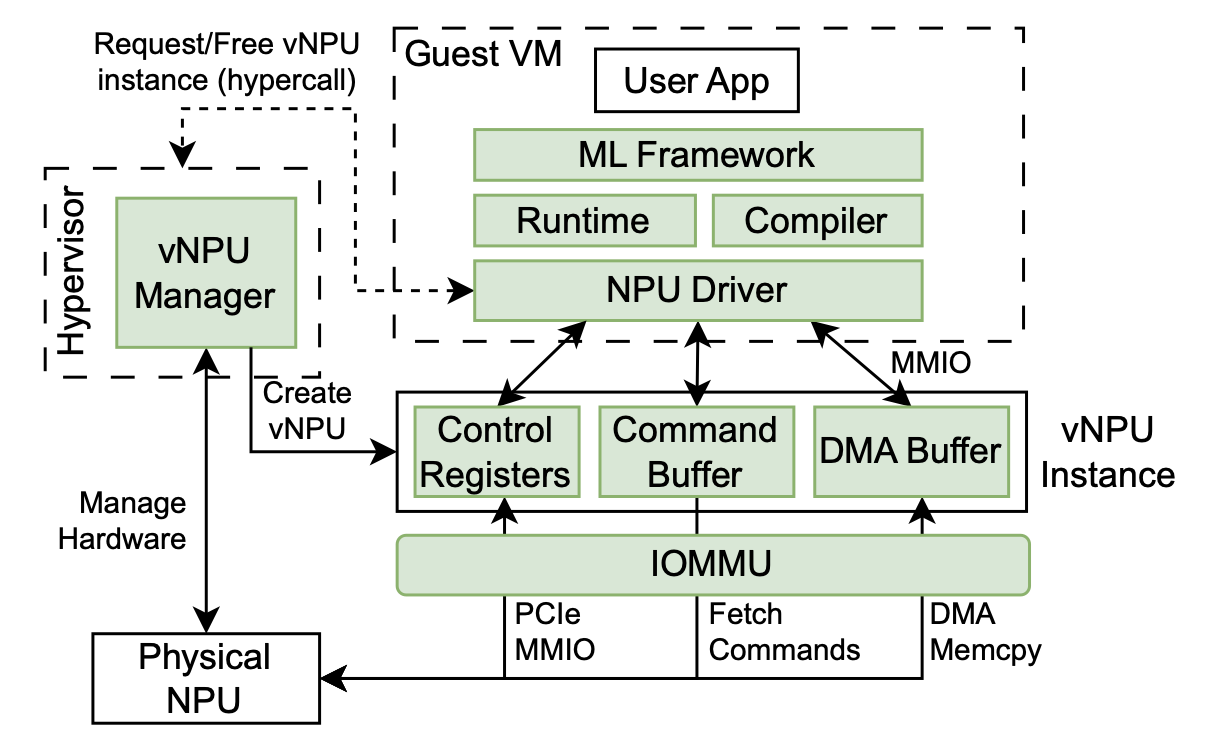
Modern cloud platforms have been employing hardware accelerators such as neural processing units (NPUs) to meet
the increasing demand for computing resources for AI-based
application services. However, due to the lack of system virtualization support, the current way of using NPUs in cloud
platforms suffers from either low resource utilization or poor
isolation between multi-tenant application services. In this
paper, we investigate the system virtualization techniques
for NPUs across the entire software and hardware stack, and
present our NPU virtualization solution.
We propose a flexible NPU abstraction named vNPU that
allows fine-grained NPU virtualization and resource management.
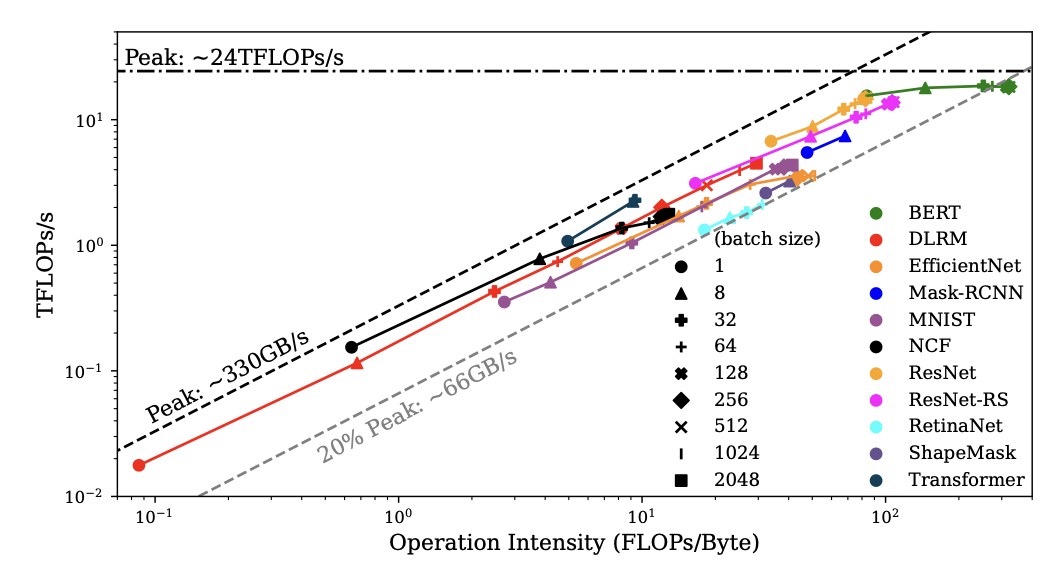
ISCA • 03/09/2023
We present V10, a hardware-assisted NPU multi-tenancy framework for improving resource utilization, while
ensuring fairness for different ML services. We rethink the NPU architecture for supporting multi-tenancy. V10 employs an operator
scheduler for enabling concurrent operator executions on the systolic array and the vector unit, and offers flexibility for enforcing
different priority-based resource-sharing mechanisms. V10 also enables fine-grained operator preemption and lightweight context
switch.
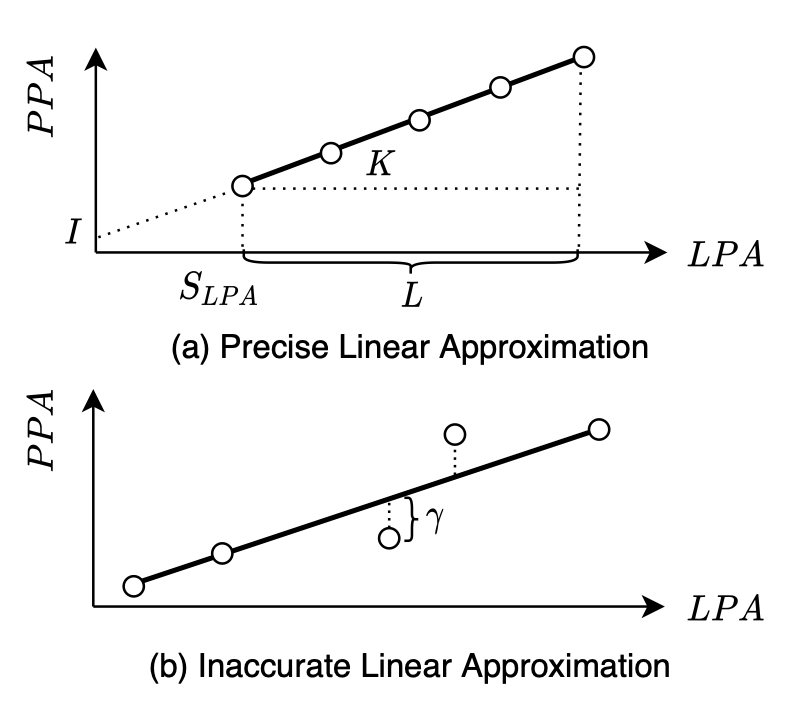
ASPLOS • 09/22/2022
we present a learning-based flash translation layer
(FTL), named LeaFTL, which learns the address mapping to tolerate
dynamic data access patterns via linear regression at runtime. By
grouping a large set of mapping entries into a learned segment, it
significantly reduces the memory footprint of the address mapping
table, which further benefits the data caching in SSD controllers.
